I finally decided to use the Raspberry Pi 4 Model B+ 8gb I had lying around to play around with some sensors. Luckily I took an electrical engineering course in circuits[ECE210 at UIC], which made it pretty straight forward to wire things up. I had also already flashed an OS to the SD card and only encountered a few issues with booting up with the pi in its case(with fan!) and the temperature/humidity sensor plugged in. Please note that setting up VNC Server(RPI) and VNC Viewer(Desktop) will speed this up dramatically. Below is a pretty simple mockup of the connection I used with the Fan’s Power on pin 4[+,5.0VDC] and pin 14[-] and the DHT11 sensor on Pin 2[+,5.0VDC], Pin 6[-], and Pin 7[GPIO7].

And here’s the setup:

As a side note, Fritzing worked really well to generate the image above and I used the build at: https://github.com/Move2win/Fritzing-0.9.9.64.pc-Compiled-Build
It is a compiled .exe on a random github repository and one should take care….. but it was definitely faster than trying to build Fritzing from source.
Next I got a basic python script working on my Raspberry Pi after installing the Adafruit_DHT library.
Installation was pretty straight forward. Enter this into the command prompt
Next:
Change directories:
Now:
Finally….:
Now create a .py file and enter the following:
Code
{python}
import Adafruit_DHT
import requests
import time
from datetime import datetime
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Buffer to store data
data_buffer = []
while True:
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
data = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
# Log data to buffer
data_buffer.append(data)
print(f"Logged data: {data}")
#clear data buffer
data_buffer.clear()
# Wait for 1 second before logging the next reading
time.sleep(1)Code Summary
This Python code snippet reads humidity and temperature data from a DHT11 sensor connected to a Raspberry Pi, formats the data with timestamps, and logs it. Here’s a breakdown of the key steps:
Imports Necessary Libraries:
Adafruit_DHTfor interfacing with the DHT11 sensor.requestsfor sending HTTP requests (though not used in this snippet).timefor managing sleep intervals.datetimefor timestamping data.
Sensor Setup:
The sensor type is defined as
DHT11.The GPIO pin to which the sensor is connected is set to
PIN = 4.
Data Buffer Initialization:
- An empty list
data_bufferis initialized to store the sensor readings.
- An empty list
Continuous Data Logging Loop:
Enters an infinite loop to continuously read data from the sensor.
Reads humidity and temperature (in Celsius) from the DHT11 sensor using
Adafruit_DHT.read_retry(SENSOR, PIN).If valid data is read (i.e., not
None), the following actions are performed:Converts the temperature from Celsius to Fahrenheit.
Gets the current date and time using
datetime.now()and formats them as strings.Prepares a dictionary
datacontaining the date, time, humidity, temperature in Celsius, and temperature in Fahrenheit.Appends the
datadictionary todata_buffer.Logs the data by printing it to the console.
Clears the
data_bufferlist to reset it for the next set of readings.
Waits for 1 second before taking the next reading using
time.sleep(1).
Overall, this code continuously monitors environmental data from a DHT11 sensor, timestamps the readings, and logs them to a buffer (though the buffer is cleared immediately in this example).
This script will grab the current date, time, Percent Humidity, Temp in Fahrenheit/Celsius and display it to the user. Note that we are appending it to a buffer which will become important later.
Next I tried various server/serverless options to get realtime data and decided on Vercel. I also tried out ThingSpeak and really liked its interface, but the fact that I would have to pay(if I wasn’t a student) made me consider other options. To implement a basic realtime logging of sensor data in ThingSpeak one would sign up for an account, create a channel, populate a channel and add field labels such as Temperature and Humidity, and save the channel to receive a unique Channel ID and API key. The code for thingspeak is pretty straightforward and one can implement the code below to populate a ThingSpeak channel.
Code
{python}
import Adafruit_DHT
import requests
import time
from datetime import datetime
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Buffer to store data
data_buffer = []
# ThingSpeak URL
base_url = 'https://api.thingspeak.com/update'
# Replace 'YOUR_API_KEY' with your actual ThingSpeak channel write API key
api_key = 'YOUR_API_KEY'
while True:
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
data = {
'api_key': api_key,
'field1': temperature_C,
'field2': temperature_F,
'field3': humidityPercent
}
# Send data to ThingSpeak
try:
response = requests.get(base_url, params=payload)
print('Data posted to ThingSpeak', response.text)
except requests.exceptions.RequestException as e:
print('Failed to send data:', e)
# Log data to buffer
data_buffer.append(data)
print(f"Logged data: {data}")
#clear data buffer
data_buffer.clear()
# Wait for 1 second before logging the next reading
time.sleep(1)Code Summary
This Python script reads environmental data from a DHT11 sensor and sends it to the ThingSpeak cloud service. Here is a summary of the main components and functionality:
Imports Necessary Libraries:
Adafruit_DHTfor interfacing with the DHT11 sensor.requestsfor making HTTP requests to ThingSpeak.timefor managing sleep intervals.datetimefor timestamping data.
Sensor Setup:
The sensor type is defined as
DHT11.The GPIO pin to which the sensor is connected is set to
PIN = 4.
Data Buffer Initialization:
- An empty list
data_bufferis initialized to store the sensor readings.
- An empty list
ThingSpeak Configuration:
The base URL for ThingSpeak updates is defined as
base_url.An API key placeholder
api_keyis set to'YOUR_API_KEY'. Replace this with your actual ThingSpeak channel write API key.
Continuous Data Logging Loop:
Enters an infinite loop to continuously read data from the sensor.
Reads humidity and temperature (in Celsius) from the DHT11 sensor using
Adafruit_DHT.read_retry(SENSOR, PIN).If valid data is read (i.e., not
None), the following actions are performed:Converts the temperature from Celsius to Fahrenheit.
Gets the current date and time using
datetime.now()and formats them as strings.Prepares a dictionary
datacontaining the API key, temperature in Celsius, temperature in Fahrenheit, and humidity.Sends the
datadictionary to ThingSpeak via a GET request usingrequests.get().Logs the response from ThingSpeak and any exceptions that occur during the request.
Logs the data to
data_bufferby appending thedatadictionary.Clears the
data_bufferlist to reset it for the next set of readings.
Waits for 1 second before taking the next reading using
time.sleep(1).
This script continuously monitors environmental data from a DHT11 sensor, sends the data to ThingSpeak, and logs the readings locally.
The resulting channel is functional enough:

Location: https://thingspeak.com/channels/2545447
Realistically, I may incorporate sending the data to ThingSpeak as well as the other option I chose for monitoring.
I got my account up and running with Vercel, installing it on a private Github repo. I then installed Node.js and npm. Then I navigated to the repo and opened up a command prompt:
I then created a ‘/api’ directory and created a file for my sensor data handling called ‘/api/sensor.js’. Note the addition of the API_KEY variable that you should add to your Vercel global environment variables to make sure there’s some added security.
Code
{javascript}
const API_KEY = process.env.API_KEY; // Retrieve the API key from environment variables
// Function for real-time data monitoring
module.exports.realTimeDataMonitoring = async (req, res) => {
if (req.method === 'POST') {
try {
// Extract API key from request headers
const providedApiKey = req.headers['x-api-key'];
// Check if API key is provided and matches the expected API key
if (!providedApiKey || providedApiKey !== API_KEY) {
return res.status(401).json({ error: 'Unauthorized' });
}
// Extract data from request body just to log and test the handling
const { temperature, humidity } = req.body;
// Log the data received to console for verification
console.log(`Received - Temperature: ${temperature}, Humidity: ${humidity}`);
// Send a successful response back to the client without any database interaction
res.status(200).json({ message: 'Data received successfully!', temperature, humidity });
} catch (e) {
// Handle errors and send an error response
console.error(e);
res.status(500).json({ error: 'An internal error occurred', details: e.message });
}
} else {
// Respond with method not allowed if not a POST request
res.status(405).json({ error: 'Method not allowed' });
}
};Code Summary
This JavaScript code defines a function for real-time data monitoring, intended to be used as part of an API in a Node.js environment. The function is exported as realTimeDataMonitoring and handles HTTP POST requests to log temperature and humidity data received from clients. Here is a summary of its main components and functionality:
API Key Retrieval:
- The API key is retrieved from environment variables using
process.env.API_KEY.
- The API key is retrieved from environment variables using
Function Definition:
- The
realTimeDataMonitoringfunction is an asynchronous function designed to handle HTTP requests, specifically POST requests.
- The
Request Handling:
- The function first checks if the request method is POST. If not, it responds with a
405 Method Not Allowedstatus.
- The function first checks if the request method is POST. If not, it responds with a
API Key Validation:
The function extracts the provided API key from the request headers (
x-api-key).It checks if the provided API key matches the expected API key. If not, it responds with a
401 Unauthorizedstatus.
Data Extraction and Logging:
If the API key is valid, the function extracts temperature and humidity data from the request body.
It logs the received data to the console for verification.
Response to Client:
- The function sends a
200 OKresponse back to the client, confirming successful data reception, along with the received temperature and humidity data.
- The function sends a
Error Handling:
- If an error occurs during the process, it catches the exception, logs the error, and responds with a
500 Internal Server Errorstatus, including the error details.
- If an error occurs during the process, it catches the exception, logs the error, and responds with a
Exporting the Function:
- The function is exported using
module.exportsfor use in other parts of the application.
- The function is exported using
This setup ensures secure and controlled data reception for real-time monitoring, with proper error handling and validation mechanisms in place.
From here I pushed the changes to github which caused the Vercel site to redeploy and changed the code on the Raspberry Pi to the following:
Code
{python}
import Adafruit_DHT
import requests
import time
from datetime import datetime
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Buffer to store data
data_buffer = []
# Vercel endpoint URL
URL = 'https://your-vercel-url.vercel.app/api/sensor'
# Define your Vercel API key
API_KEY = 'YOUR_API_KEY'
while True:
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
data = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
# Send data to Vercel
try:
# Send the data to the server with the API key in the headers
headers = {'x-api-key': API_KEY}
response = requests.post(URL, json=data, headers=headers)
print(f"Data sent to server: {response.text}")
except requests.exceptions.RequestException as e:
# Handle exceptions that arise from sending the request
print(f"Failed to send data to server: {e}")
else:
# Handle cases where sensor fails to read
print("Failed to retrieve data from sensor")
# Wait for 1 second before logging the next reading
time.sleep(1)Code Summary
This Python script reads environmental data from a DHT11 sensor and sends it to a Vercel endpoint for real-time monitoring. Here are the main components and functionalities of the script:
Imports Necessary Libraries:
Adafruit_DHTfor interfacing with the DHT11 sensor.requestsfor making HTTP POST requests to the Vercel endpoint.timefor managing sleep intervals.datetimefor timestamping data.
Sensor Setup:
Defines the sensor type as
DHT11.Sets the GPIO pin connected to the sensor as
PIN = 4.
Data Buffer Initialization:
- Initializes an empty list
data_bufferto store the sensor readings (though it is not used in this script).
- Initializes an empty list
Vercel Configuration:
Defines the Vercel endpoint URL (
URL).Sets an API key (
API_KEY) for authenticating with the Vercel endpoint.
Continuous Data Logging Loop:
Enters an infinite loop to continuously read data from the sensor.
Reads humidity and temperature (in Celsius) from the DHT11 sensor using
Adafruit_DHT.read_retry(SENSOR, PIN).If valid data is read (i.e., not
None), the following actions are performed:Converts the temperature from Celsius to Fahrenheit.
Gets the current date and time using
datetime.now()and formats them as strings.Prepares a dictionary
datacontaining the date, time, humidity, temperature in Celsius, and temperature in Fahrenheit.Sends the
datadictionary to the Vercel endpoint via a POST request usingrequests.post().Prints the server’s response to the console.
Catches and handles any exceptions that arise from sending the request, printing an error message if the request fails.
If the sensor fails to read data, it prints an error message.
Waits for 1 second before taking the next reading using
time.sleep(1).
This script continuously monitors environmental data from a DHT11 sensor, sends the data to a Vercel endpoint for real-time monitoring, and logs the readings locally. It includes error handling for both sensor read failures and HTTP request failures.
I will omit the fact that I spent forever trying to also get MongoDB to work within Vercel and later found out that I needed to perform some sort of installation to get it to work. I did however find out that Vercel offered a PostgreSQL implementation so I could store my data as it came in. I navigated to Storage and found it was a few pretty simple clicks to get it going.
I created a table using:
{sql}
CREATE TABLE readings (
id SERIAL PRIMARY KEY,
Date DATE NOT NULL,
Time TIME NOT NULL,
humidityPercent FLOAT NOT NULL,
temperatureFahrenheit FLOAT NOT NULL,
temperatureCelsius FLOAT NOT NULL,
);And extended sensor.js a bit…Namely I edited it so it can handle a data_buffer of multiple points as well as singular points to cut down on server connection overhead. I also added some logging for the sake of sanity on the off chance anything ever goes wrong.
Note, you need to install pg on your github directory for PostgreSQL to work.
Code
{javascript}
const API_KEY = process.env.API_KEY; // Retrieve the API key from environment variables
console.log('API Key:', API_KEY); // For debugging purposes
const { Pool } = require('pg');
// PostgreSQL connection setup
const pool = new Pool({
connectionString: process.env.POSTGRES_URL, // Make sure to set this environment variable in Vercel
ssl: {
rejectUnauthorized: false
}
});
// Function to handle logging and appending data to PostgreSQL
const handleSensorData = async (req, res) => {
if (req.method !== 'POST') {
return res.status(405).json({ error: 'Method not allowed' });
}
try {
console.log('Request received'); // For debugging purposes
// Extract API key from request headers
const providedApiKey = req.headers['x-api-key'];
console.log('Provided API Key:', providedApiKey); // For debugging purposes
// Check if API key is provided and matches the expected API key
if (!providedApiKey || providedApiKey !== API_KEY) {
return res.status(401).json({ error: 'Unauthorized' });
}
// Extract data from request body
const data = req.body;
// Log the data received to console for verification
console.log('Received data:', JSON.stringify(data, null, 2));
let query;
let values;
// Check if data is an array (multiple readings) or a single reading
if (Array.isArray(data)) {
// SQL query to insert multiple readings
query = `
INSERT INTO readings (temperatureCelsius, temperatureFahrenheit, humidityPercent, date, time)
VALUES ${data.map((_, index) => `($${index * 5 + 1}, $${index * 5 + 2}, $${index * 5 + 3}, $${index * 5 + 4}, $${index * 5 + 5})`).join(', ')}
RETURNING *;
`;
// Flatten the array of data into a single array of values
values = data.flatMap(({ temperatureCelsius, temperatureFahrenheit, humidityPercent, date, time }) => [
temperatureCelsius !== null && temperatureCelsius !== undefined ? temperatureCelsius : 0,
temperatureFahrenheit !== null && temperatureFahrenheit !== undefined ? temperatureFahrenheit : 0,
humidityPercent !== null && humidityPercent !== undefined ? humidityPercent : 0,
date !== null && date !== undefined ? date : new Date().toISOString().split('T')[0],
time !== null && time !== undefined ? time : new Date().toISOString().split('T')[1].split('.')[0]
]);
} else {
// SQL query to insert a single reading
query = `
INSERT INTO readings (temperatureCelsius, temperatureFahrenheit, humidityPercent, date, time)
VALUES ($1, $2, $3, $4, $5)
RETURNING *;
`;
// Single reading values
values = [
data.temperatureCelsius !== null && data.temperatureCelsius !== undefined ? data.temperatureCelsius : 0,
data.temperatureFahrenheit !== null && data.temperatureFahrenheit !== undefined ? data.temperatureFahrenheit : 0,
data.humidityPercent !== null && data.humidityPercent !== undefined ? data.humidityPercent : 0,
data.date !== null && data.date !== undefined ? data.date : new Date().toISOString().split('T')[0],
data.time !== null && data.time !== undefined ? data.time : new Date().toISOString().split('T')[1].split('.')[0]
];
}
// Execute the query
const result = await pool.query(query, values);
console.log('Data stored in PostgreSQL:', result.rows);
// Send a successful response back to the client
res.status(200).json({ message: 'Data received and stored successfully!', data: result.rows });
} catch (e) {
// Handle errors and send an error response
console.error("Error connecting to PostgreSQL or inserting data:", e);
res.status(500).json({ error: 'Failed to connect to database or insert data', details: e.message });
}
};
// Export the function for Vercel
module.exports = handleSensorData;Code Summary
This JavaScript code handles real-time sensor data logging and storage in a PostgreSQL database. It is designed to be used in a Node.js environment and is likely intended to run on Vercel. Here is a summary of the main components and functionality:
API Key Retrieval:
- The API key is retrieved from environment variables using
process.env.API_KEY.
- The API key is retrieved from environment variables using
Debugging Logs:
- Logs the API key and other debugging information to the console.
PostgreSQL Connection Setup:
Uses the
pglibrary to create a connection pool to the PostgreSQL database.The connection string is retrieved from the
POSTGRES_URLenvironment variable.SSL connection is configured with
rejectUnauthorized: false.
Function to Handle Sensor Data:
The function
handleSensorDatais exported for use in Vercel.It handles HTTP POST requests to log and store sensor data.
Request Handling:
Checks if the request method is POST. If not, it responds with a
405 Method Not Allowedstatus.Extracts the provided API key from the request headers and logs it for debugging.
Compares the provided API key with the expected API key. If they do not match, it responds with a
401 Unauthorizedstatus.
Data Extraction and Logging:
- Extracts the sensor data from the request body and logs it to the console for verification.
SQL Query Preparation:
Prepares an SQL query to insert the sensor data into the
readingstable in PostgreSQL.Supports both single reading and multiple readings (batch) insertions.
Constructs the query and flattens the data array for batch insertions.
Database Insertion:
Executes the SQL query using the connection pool.
Logs the inserted data to the console.
Response to Client:
- Sends a
200 OKresponse back to the client, confirming successful data reception and storage, along with the inserted data.
- Sends a
Error Handling:
Catches any exceptions that occur during the database connection or data insertion.
Logs the error and responds with a
500 Internal Server Errorstatus, including error details.
This script ensures secure, real-time logging of sensor data, with proper validation and error handling, and stores the data in a PostgreSQL database.
From there what my final product looks like is an html page which displays the latest sensor readings, a javascript function to pull the entire dataset, a javascript function which pushes the data into the database, and the python script on the raspberry pi sending the data. I actually bunch up the data before I push it to save on the overhead costs of establishing a connection. Realistically the data isn’t too time sensitive and a window of 1-5 minutes is perfectly acceptable for readings. They are below:
Html:
Code
{html}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Download Table Data</title>
<style>
/* CSS to style the table with borders */
table {
border-collapse: collapse;
width: 100%;
}
th, td {
border: 1px solid #dddddd;
text-align: left;
padding: 8px;
}
th {
background-color: #f2f2f2;
}
</style>
</head>
<body>
<h1>Download Table Data</h1>
<a href="/api/displaySQL">Download Table Data as CSV</a>
<h2>Current Readings</h2>
<table id="currentReadings">
<tr>
<th>Date</th>
<th>Time</th>
<th>Humidity (%)</th>
<th>Temperature (F)</th>
<th>Temperature (C)</th>
</tr>
</table>
<script>
// Function to format the date
function formatDate(dateString) {
const date = new Date(dateString);
return date.toLocaleDateString('en-US');
}
// Fetch the last row data from the serverless function
fetch('/api/displayLastRowSQL')
.then(response => response.json())
.then(data => {
// Extract the relevant data from the last row
const time = data.time;
const humidity = data.humiditypercent;
const temperatureF = data.temperaturefahrenheit;
const temperatureC = data.temperaturecelsius;
const date = formatDate(data.date);
// Display the data in the HTML table
const currentReadingsTable = document.getElementById('currentReadings');
const newRow = currentReadingsTable.insertRow();
newRow.innerHTML = `
<td>${date}</td>
<td>${time}</td>
<td>${humidity}</td>
<td>${temperatureF}</td>
<td>${temperatureC}</td>
`;
})
.catch(error => {
// Handle errors
console.error('Error fetching current readings:', error);
});
</script>
</body>
</html>Javascript to pull entire dataset:
Code
{javascript}
// Import the necessary libraries
const { Pool } = require('pg');
const { Parser } = require('json2csv');
// PostgreSQL connection setup
const pool = new Pool({
connectionString: process.env.POSTGRES_URL, // Make sure to set this environment variable in Vercel
ssl: {
rejectUnauthorized: false
}
});
// Serverless function exported for Vercel //note slow loop of formatted rows. FIX!!!!
module.exports = async (req, res) => {
try {
// SQL Query to select all records from the table
const query = 'SELECT * FROM readings';
// Execute the query
const result = await pool.query(query);
// Format the date field in each row
const formattedRows = result.rows.map(row => {
const formattedDate = row.date ? new Date(row.date).toLocaleDateString('en-US') : ''; // Format date to locale string (excluding time)
return { ...row, date: formattedDate };
});
// Convert the formatted rows to CSV format
const json2csvParser = new Parser();
const csvData = json2csvParser.parse(formattedRows);
// Set response headers to indicate a CSV file download
res.setHeader('Content-Type', 'text/csv');
res.setHeader('Content-Disposition', 'attachment; filename="table_data.csv"');
// Send the CSV data as the response
res.status(200).send(csvData);
} catch (error) {
// Handle errors and send an error response
console.error("Error fetching data from PostgreSQL:", error);
res.status(500).json({ error: 'Failed to fetch data from database', details: error.message });
}
};Code Summary
This JavaScript code defines a serverless function that fetches data from a PostgreSQL database, formats the data, converts it to CSV format, and sends it as a downloadable file in the HTTP response. It is designed to be deployed on Vercel. Here is a summary of the main components and functionality:
Import Necessary Libraries:
pgfor connecting to the PostgreSQL database.json2csvfor converting JSON data to CSV format.
PostgreSQL Connection Setup:
Uses the
pglibrary to create a connection pool to the PostgreSQL database.The connection string is retrieved from the
POSTGRES_URLenvironment variable.SSL connection is configured with
rejectUnauthorized: false.
Serverless Function Exported for Vercel:
- The function is exported to be used as a serverless function in Vercel.
Fetching Data from PostgreSQL:
Defines an SQL query to select all records from the
readingstable.Executes the query using the connection pool and stores the result.
Formatting Data:
Formats the
datefield in each row to a locale date string (excluding time).Uses
Array.map()to iterate over each row and apply the date formatting.
Converting Data to CSV:
Uses
json2csvto convert the formatted JSON data to CSV format.Initializes a
Parserobject and calls theparse()method with the formatted rows.
Setting Response Headers for CSV Download:
Sets the
Content-Typeheader totext/csv.Sets the
Content-Dispositionheader to indicate a file download with the filenametable_data.csv.
Sending the CSV Data as Response:
- Sends the CSV data as the HTTP response with a
200 OKstatus.
- Sends the CSV data as the HTTP response with a
Error Handling:
Catches any errors that occur during data fetching or processing.
Logs the error and responds with a
500 Internal Server Errorstatus, including error details.
This script ensures that data from the PostgreSQL database is formatted and made available for download as a CSV file, with proper error handling to manage potential issues during execution.
Javascript to display latest sensor readings:
Code
{javascript}
// Import the necessary libraries
const { Pool } = require('pg');
// PostgreSQL connection setup
const pool = new Pool({
connectionString: process.env.POSTGRES_URL, // Make sure to set this environment variable in Vercel
ssl: {
rejectUnauthorized: false
}
});
// Serverless function exported for Vercel
module.exports = async (req, res) => {
try {
// SQL Query to select the last row from the table with the specified order
const query = `
SELECT time,
humiditypercent,
temperaturefahrenheit,
temperaturecelsius,
date
FROM readings
ORDER BY id DESC
LIMIT 1
`;
// Execute the query
const result = await pool.query(query);
// Check if result.rows is not empty
if (result.rows.length === 0) {
res.status(404).json({ error: 'No data found in the database' });
return;
}
// Format the date field to 'YYYY-MM-DD'
const row = result.rows[0];
row.date = row.date ? new Date(row.date).toLocaleDateString('en-us').slice(0, 10) : 'Invalid date';
// Debugging: Log the formatted date to inspect it
console.log("Formatted date:", row.date);
// Send the last row data as the response
res.status(200).json(row); // Assuming there is at least one row in the table
} catch (error) {
// Handle errors and send an error response
console.error("Error fetching data from PostgreSQL:", error);
res.status(500).json({ error: 'Failed to fetch data from database', details: error.message });
}
};Code Summary
This JavaScript code defines a serverless function that fetches the most recent data entry from a PostgreSQL database and returns it as a JSON response. It is designed to be deployed on Vercel. Here is a summary of the main components and functionality:
Import Necessary Libraries:
pgfor connecting to the PostgreSQL database.
PostgreSQL Connection Setup:
Uses the
pglibrary to create a connection pool to the PostgreSQL database.The connection string is retrieved from the
POSTGRES_URLenvironment variable.SSL connection is configured with
rejectUnauthorized: false.
Serverless Function Exported for Vercel:
- The function is exported to be used as a serverless function in Vercel.
Fetching the Latest Data from PostgreSQL:
Defines an SQL query to select the last row from the
readingstable, ordered by theidcolumn in descending order.Limits the query to return only one row (
LIMIT 1).
Executing the SQL Query:
- Executes the query using the connection pool and stores the result.
Checking if Data is Available:
Checks if the
result.rowsarray is not empty.If no data is found, responds with a
404 Not Foundstatus and an error message.
Formatting the Date Field:
Formats the
datefield in the retrieved row to the ‘YYYY-MM-DD’ format.Uses
new Date(row.date).toLocaleDateString('en-us').slice(0, 10)to format the date, ensuring only the date part is included.
Debugging Log:
- Logs the formatted date to the console for inspection.
Sending the Data as Response:
- Sends the retrieved and formatted data as the HTTP response with a
200 OKstatus.
- Sends the retrieved and formatted data as the HTTP response with a
Error Handling:
Catches any errors that occur during data fetching or processing.
Logs the error and responds with a
500 Internal Server Errorstatus, including error details.
This script ensures that the most recent data entry from the PostgreSQL database is retrieved, formatted, and returned as a JSON response, with proper error handling to manage potential issues during execution. The debugging log provides insight into the formatted date for verification.
Python script on the raspberry pi:
Code
{python}
import Adafruit_DHT
import requests
import time
from datetime import datetime
# Define your Vercel API key
API_KEY = 'YOUR_API_KEY'
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Vercel endpoint URL
URL = 'https://your-vercel-url.vercel.app/api/sensor'
# Buffer to store data
data_buffer = []
i = 1
def send_data(data):
"""Send data to the server."""
try:
# Include API key in the headers
headers = {'X-API-Key': API_KEY}
response = requests.post(URL, json=data, headers=headers)
print(f"Data sent to server: {response.text}")
except requests.exceptions.RequestException as e:
print(f"Failed to send data to server: {e}")
while True:
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
data = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
# Log data to buffer
data_buffer.append(data)
if i % 60 == 0:
print(f"Logged data: {data}")
# Check if 300 seconds have passed
if len(data_buffer) >= 300:
send_data(data_buffer)
# Clear the buffer after sending
data_buffer.clear()
i = 0
else:
# Handle cases where sensor fails to read
print("Failed to retrieve data from sensor")
# Wait for 1 second before logging the next reading
time.sleep(1)
i += 1Code
This Python script reads environmental data from a DHT11 sensor every second, stores it in a buffer, and sends the buffered data to a Vercel endpoint every 5 minutes (300 seconds). The script includes error handling for sensor read failures and HTTP request failures. Here is a summary of the main components and functionality:
Imports Necessary Libraries:
Adafruit_DHTfor interfacing with the DHT11 sensor.requestsfor making HTTP POST requests to the Vercel endpoint.timefor managing sleep intervals.datetimefor timestamping data.
Vercel API Key and Endpoint Setup:
- Defines the Vercel API key (
API_KEY) and endpoint URL (URL).
- Defines the Vercel API key (
Sensor Setup:
Defines the sensor type as
DHT11.Sets the GPIO pin connected to the sensor (
PIN = 4).
Buffer Initialization:
Initializes an empty list
data_bufferto store sensor readings.Initializes a counter
ito keep track of the number of readings.
Data Sending Function:
send_data(data): Sends the buffered data to the Vercel endpoint.Includes the API key in the request headers.
Sends the data using an HTTP POST request.
Logs the response or any exceptions that occur.
Continuous Data Logging Loop:
Enters an infinite loop to continuously read data from the sensor every second.
Reads humidity and temperature (in Celsius) from the DHT11 sensor using
Adafruit_DHT.read_retry(SENSOR, PIN).If valid data is read (i.e., not
None), the following actions are performed:Converts the temperature from Celsius to Fahrenheit.
Gets the current date and time using
datetime.now()and formats them as strings.Prepares a dictionary
datacontaining the date, time, humidity, temperature in Celsius, and temperature in Fahrenheit.Appends the
datadictionary todata_buffer.Logs the data to the console every 60 readings.
Checks if 300 readings (300 seconds) have been collected.
If so, calls
send_data(data_buffer)to send the buffered data to the Vercel endpoint.Clears the
data_bufferand resets the counteri.
If the sensor fails to read data, it logs an error message.
Waits for 1 second before taking the next reading using
time.sleep(1).Increments the counter
iwith each iteration.
This script ensures continuous monitoring and logging of environmental data from a DHT11 sensor, with periodic transmission of the data to a Vercel endpoint for real-time monitoring or further processing.
I intend to add more sensors such as a VOC sensor, CO2 sensor, PM2.5/PM10 sensor to have real time air quality data. That should be plug and play and a few lines of code. Getting the raspberry pi, server, and database to get along is a lot more work than wiring up a few sensors. I will also likely throw the data into a mongoDB and also push the data to ThingSpeak regularly once I have figured out what the best storage medium is. Unfortunately server uptime is counted as compute time for the purpose of using PostgreSQL in Vercel, so its great for testing, but definitely won’t be my long term solution. I might just do the unhinged option and use Google Sheets as a database. It should be possible to have up to 10 million cells which, when coupled with the data being logged at Date, Time, Humidity, TempF, and TempC that means I can have roughly 2 million rows before I need to think of pushing to another sheet. With a safety factor of 2 I have 1 million and that means I have 1,000,000/60 = 16,666 seconds/60 = 277 hours/24 = 11.5 days of data before I need to consider using another sheet. I can likely shorten this to 7 days and dynamically generate a new sheet every week.
**Edit**: I actually went ahead and tried the google sheets option. Created a Google Cloud Project, enabled the Google Sheets API, and created credentials/downloaded the resultant JSON.
I also had to make sure some Google Python libraries were installed:
Next I implemented a pretty basic program to send a few values to a Google Sheet:
Code
{python}
import os
import google.auth
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from datetime import datetime
# Define the scopes required for the Google Sheets API
SCOPES = ['https://www.googleapis.com/auth/spreadsheets']
# Function to get authenticated service
def get_sheets_service():
creds = None
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.json', 'w') as token:
token.write(creds.to_json())
service = build('sheets', 'v4', credentials=creds)
return service
# Function to create a new Google Sheet with a given name
def create_new_sheet(sheet_name):
service = get_sheets_service()
spreadsheet = {
'properties': {
'title': sheet_name
}
}
spreadsheet = service.spreadsheets().create(body=spreadsheet, fields='spreadsheetId').execute()
print(f"Created new spreadsheet with ID: {spreadsheet.get('spreadsheetId')}, Name: {sheet_name}")
return spreadsheet.get('spreadsheetId')
# Function to check the number of cells in the Google Sheet and create a new one if it doesn't exist
def check_sheet_size(spreadsheet_id, new_sheet_name):
service = get_sheets_service()
try:
sheet = service.spreadsheets().get(spreadsheetId=spreadsheet_id).execute()
sheets = sheet.get('sheets', [])
except HttpError as e:
print(f"HttpError encountered: Status code: {e.resp.status}, Reason: {e.error_details}")
if e.resp.status == 404:
print(f"Spreadsheet with ID '{spreadsheet_id}' not found. Creating a new sheet.")
return create_new_sheet(new_sheet_name), 0
else:
raise
total_cells = 0
for sheet in sheets:
properties = sheet.get('properties', {})
grid_properties = properties.get('gridProperties', {})
rows = grid_properties.get('rowCount', 0)
cols = grid_properties.get('columnCount', 0)
total_cells += rows * cols
return spreadsheet_id, total_cells
# Function to read data from a Google Sheet
def read_data(spreadsheet_id, range_name):
service = get_sheets_service()
result = service.spreadsheets().values().get(spreadsheetId=spreadsheet_id, range=range_name).execute()
rows = result.get('values', [])
return rows
# Function to write data to a Google Sheet
def write_data(spreadsheet_id, range_name, values):
service = get_sheets_service()
body = {
'values': values
}
result = service.spreadsheets().values().update(
spreadsheetId=spreadsheet_id, range=range_name,
valueInputOption='RAW', body=body).execute()
return result
# Function to append data to a Google Sheet
def append_data(spreadsheet_id, range_name, values):
service = get_sheets_service()
body = {
'values': values
}
result = service.spreadsheets().values().append(
spreadsheetId=spreadsheet_id, range=range_name,
valueInputOption='RAW', body=body).execute()
return result
# Function to delete data in a Google Sheet
def clear_data(spreadsheet_id, range_name):
service = get_sheets_service()
result = service.spreadsheets().values().clear(spreadsheetId=spreadsheet_id, range=range_name).execute()
return result
def main():
spreadsheet_id = 'your-spreadsheet-id' # Replace with your Google Sheet ID
read_range = 'Sheet1!A1:E5'
write_range = 'Sheet1!A1'
append_range = 'Sheet1!A1'
clear_range = 'Sheet1!A1:E5'
max_cells = 5000000
# Get current date and time
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
new_sheet_name = f"Pi-Sensor {current_time}" # New sheet name with date and time
# Check sheet size and create new sheet if necessary
spreadsheet_id, total_cells = check_sheet_size(spreadsheet_id, new_sheet_name)
print(f"Total cells in the sheet: {total_cells}")
if total_cells >= max_cells:
print("The sheet has reached the maximum cell limit. Creating a new sheet.")
spreadsheet_id = create_new_sheet(new_sheet_name)
else:
print("The sheet has not reached the maximum cell limit.")
# Reading data
rows = read_data(spreadsheet_id, read_range)
print("Read data:")
for row in rows:
print(row)
# Writing data
values_to_write = [
['Name', 'Age', 'City'],
['John Doe', '30', 'New York'],
['Jane Smith', '25', 'Los Angeles']
]
write_result = write_data(spreadsheet_id, write_range, values_to_write)
print(f"Data written: {write_result}")
# Appending data
values_to_append = [
['Alice', '35', 'Chicago'],
['Bob', '40', 'San Francisco']
]
append_result = append_data(spreadsheet_id, append_range, values_to_append)
print(f"Data appended: {append_result}")
# # Clearing data
# clear_result = clear_data(spreadsheet_id, clear_range)
# print(f"Data cleared: {clear_result}")
if __name__ == '__main__':
main()Code Summary
This Python script provides functionalities to interact with Google Sheets using the Google Sheets API. It includes authentication, creating new sheets, checking sheet size, reading data, writing data, appending data, and clearing data in a Google Sheet. Here is a summary of the main components and functionality:
Key Components:
Imports and Authentication:
Imports necessary libraries for Google Sheets API, Google authentication, and handling HTTP errors.
Defines the scope required for accessing the Google Sheets API.
Authentication Function:
get_sheets_service(): Authenticates the user using OAuth 2.0 and returns a service object for interacting with Google Sheets.
Create New Google Sheet:
create_new_sheet(sheet_name): Creates a new Google Sheet with the given name and returns its spreadsheet ID.
Check Sheet Size:
check_sheet_size(spreadsheet_id, new_sheet_name): Checks the number of cells in the specified Google Sheet and creates a new sheet if the current sheet doesn’t exist or has reached the maximum cell limit.
Read Data from Google Sheet:
read_data(spreadsheet_id, range_name): Reads data from the specified range in the Google Sheet and returns the rows of data.
Write Data to Google Sheet:
write_data(spreadsheet_id, range_name, values): Writes the provided values to the specified range in the Google Sheet.
Append Data to Google Sheet:
append_data(spreadsheet_id, range_name, values): Appends the provided values to the specified range in the Google Sheet.
Clear Data in Google Sheet:
clear_data(spreadsheet_id, range_name): Clears data in the specified range in the Google Sheet.
Main Function:
Initialization:
Specifies the Google Sheet ID (
spreadsheet_id) and various ranges for reading, writing, appending, and clearing data.Defines the maximum number of cells allowed (
max_cells).
Current Date and Time:
- Retrieves the current date and time to create a unique name for new sheets.
Check and Create Sheet:
- Checks the size of the specified sheet and creates a new sheet if necessary.
Read Data:
- Reads data from the specified range and prints it.
Write Data:
- Writes a set of values to the specified range in the Google Sheet.
Append Data:
- Appends another set of values to the specified range in the Google Sheet.
Clear Data (Commented Out):
- Optionally clears data in the specified range.
Script Execution:
- The
main()function is called when the script is executed, performing the above operations sequentially.
Example Output:
- The script provides feedback through print statements, indicating the creation of new sheets, reading data, writing data, appending data, and handling errors.
Notes:
Replace
'your-spreadsheet-id'with your actual Google Sheet ID.Ensure you have
token.jsonfor storing the user’s access and refresh tokens.
This script facilitates seamless interaction with Google Sheets, allowing for efficient data management and automation of tasks.
Once I was assured that the Google Sheets API was functioning correctly I tweaked the existing Python code to also send data to a Google Sheet. The sheet was set to read only globally so I could later on access it via my github.io site or similar via javascript. I also added a *.txt file for persistence across runs where that sheet contains my spreadsheet_id, workbook_name, and sheet_name so I can start and stop the Python script whenever I wanted. I also added back in the ThingSpeak code from before with two additional parameters, date and time. That way I can bypass the 15second update limit of ThingSpeak by sending bulk data every 15 seconds and I can also use the date/time parameters to generate a plot on the off chance that the datasent uses the timestamp of receipt as the X axis when plotting. The final result is the plot below:

The Matlab code used:
Code
{matlab}
% Template MATLAB code for visualizing data from a channel as a 2D line
% plot using PLOT function.
% Prior to running this MATLAB code template, assign the channel variables.
% Set 'readChannelID' to the channel ID of the channel to read from.
% Also, assign the read field ID to 'fieldID1'.
% TODO - Replace the [] with channel ID to read data from:
readChannelID = 2545447;
% TODO - Replace the [] with the Field ID to read data from:
fieldID1 = 1;
fieldID2 = 2;
fieldID3 = 3;
fieldID4 = 4;
fieldID5 = 5;
% Channel Read API Key
% If your channel is private, then enter the read API
% Key between the '' below:
readAPIKey = '';
%% Read Data %%
[data, time] = thingSpeakRead(readChannelID, 'Field', fieldID1, 'NumPoints', 2400, 'ReadKey', readAPIKey);
[data2, time] = thingSpeakRead(readChannelID, 'Field', fieldID2, 'NumPoints', 2400, 'ReadKey', readAPIKey);
[data3, time] = thingSpeakRead(readChannelID, 'Field', fieldID3, 'NumPoints', 2400, 'ReadKey', readAPIKey);
[data4, time] = thingSpeakRead(readChannelID, 'Field', fieldID4, 'NumPoints', 2400, 'ReadKey', readAPIKey,'OutputFormat', 'timetable');
[data5, ~] = thingSpeakRead(readChannelID, 'Field', fieldID5, 'NumPoints', 2400, 'ReadKey', readAPIKey,'OutputFormat', 'timetable');
%disp("data4")
%disp(data4)
%disp("data5")
%disp(data5)
% Convert timestamps to datetime
timeComponents = split(data4.Time, ':');
hour = str2double(timeComponents(:,1));
minute = str2double(timeComponents(:,2));
second = str2double(timeComponents(:,3));
timeOfDay = duration(hour, minute, second);
dateTime = data5.Timestamps + timeOfDay;
% Trim or interpolate data if necessary to match the length of timeData
data = data(1:length(dateTime));
data2 = data2(1:length(dateTime));
data3 = data3(1:length(dateTime));
% Visualize Data
figure;
plot(dateTime, [data, data2, data3]);
xlabel('');
ylabel('Data');
title('ThingSpeak Data');
legend('Temp_C', 'Temp_F', 'Humidity%', 'Location', 'eastoutside');Code Summary
This MATLAB script visualizes data from a ThingSpeak channel as a 2D line plot. The script reads data from multiple fields of the specified ThingSpeak channel, processes the timestamps, and then plots the data. Here is a detailed summary of the script:
Key Components:
Channel Configuration:
readChannelID: The ID of the ThingSpeak channel to read data from.fieldID1tofieldID5: The field IDs from which data will be read.readAPIKey: The API key to access the channel (if it is private).
Reading Data:
thingSpeakRead: Reads data from the specified channel fields, up to 2400 points.
Processing Timestamps:
Converts the timestamps into a format that MATLAB can use for plotting.
Combines the date from one field with the time from another to create a datetime array.
Data Trimming:
- Ensures that the data arrays match in length to avoid plotting issues.
Plotting Data:
- Uses the
plotfunction to create a 2D line plot of the data.
- Uses the
Adds labels, a title, and a legend to the plot.
Explanation:
Channel and Field Setup:
Replace
readChannelIDandfieldID1tofieldID5with your actual ThingSpeak channel ID and field IDs.If the channel is private, provide the
readAPIKey.
Reading Data:
The
thingSpeakReadfunction is used to read data from each specified field.The ‘NumPoints’ parameter limits the data to the latest 2400 points.
Timestamp Processing:
Extracts and splits the time components (hours, minutes, and seconds) from
data4.Time.Creates a
durationarray for the time of day and combines it withdata5.Timestampsto form adatetimearray.
Data Trimming:
- Ensures all data arrays (
data,data2,data3) match the length ofdateTimeto avoid issues in plotting.
- Ensures all data arrays (
Plotting:
Creates a line plot of the data with the time on the x-axis and the data values on the y-axis.
Adds labels to the x and y axes, a title to the plot, and a legend.
This script provides a clear and structured way to visualize data from multiple fields of a ThingSpeak channel in MATLAB. Adjust the channel ID, field IDs, and API key as needed for your specific use case.
Now as far as the Python code goes, it is pretty lengthy at this point so buyer beware:
Code
{python}
import os
import time as time_module
import requests
from datetime import datetime
import random
import json
import Adafruit_DHT
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# Control flags
SEND_TO_VERCEL = True
SEND_TO_GOOGLE_SHEETS = True
SEND_TO_THINGSPEAK = True
# ThingSpeak API settings
THINGSPEAK_API_KEY = 'KEY' # Replace with your ThingSpeak API key
THINGSPEAK_BASE_URL = 'https://api.thingspeak.com/update'
VERCEL_API_KEY = 'SETMEUPINENVIRONMENTVARIABLES'
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Vercel endpoint URL
URL = 'YOURURL'
# Buffer to store data
data_buffer = []
thingspeak_buffer = [] # Buffer for ThingSpeak data
# Define loop time in seconds
LOOP_TIME = 1 # You can change this to the desired loop time in seconds
# Define the scopes required for the Google Sheets and Drive APIs
SCOPES = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive.file'
]
# Global variable to hold credentials
creds = None
# Function to get authenticated Sheets service
def get_sheets_service():
global creds
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.json', 'w') as token:
token.write(creds.to_json())
return build('sheets', 'v4', credentials=creds)
# Function to get authenticated Drive service
def get_drive_service():
global creds
if creds is None:
get_sheets_service() # This will initialize creds
return build('drive', 'v3', credentials=creds)
# Function to set a Google Sheet's permissions to public
def set_sheet_public(spreadsheet_id):
drive_service = get_drive_service()
permission = {
'type': 'anyone',
'role': 'reader'
}
try:
drive_service.permissions().create(fileId=spreadsheet_id, body=permission).execute()
print(f"Set spreadsheet with ID {spreadsheet_id} to public")
except HttpError as error:
print(f"An error occurred: {error}")
# Function to create a new Google Sheet with a given name
def create_new_sheet(sheet_name):
service = get_sheets_service()
spreadsheet = {
'properties': {
'title': sheet_name
}
}
spreadsheet = service.spreadsheets().create(body=spreadsheet, fields='spreadsheetId').execute()
spreadsheet_id = spreadsheet.get('spreadsheetId')
print(f"Created new spreadsheet with ID: {spreadsheet_id}, Name: {sheet_name}")
# Set the new sheet to be publicly viewable
set_sheet_public(spreadsheet_id)
# Save the new spreadsheet info
save_spreadsheet_info(spreadsheet_id, sheet_name, "Sheet1")
return spreadsheet_id
# Function to check the number of cells in the Google Sheet and create a new one if it doesn't exist
def check_sheet_size(spreadsheet_id, new_sheet_name):
service = get_sheets_service()
try:
sheet = service.spreadsheets().get(spreadsheetId=spreadsheet_id).execute()
sheets = sheet.get('sheets', [])
except HttpError as e:
print(f"HttpError encountered: Status code: {e.resp.status}, Reason: {e.error_details}")
if e.resp.status == 404:
print(f"Spreadsheet with ID '{spreadsheet_id}' not found. Creating a new sheet.")
return create_new_sheet(new_sheet_name), 0
else:
raise
total_cells = 0
for sheet in sheets:
properties = sheet.get('properties', {})
grid_properties = properties.get('gridProperties', {})
rows = grid_properties.get('rowCount', 0)
cols = grid_properties.get('columnCount', 0)
total_cells += rows * cols
return spreadsheet_id, total_cells
# Function to find the last empty row in the Google Sheet
def find_last_empty_row(service, spreadsheet_id, sheet_name):
max_retries = 5
retry_count = 0
backoff_factor = 2
range_name = f"{sheet_name}!A:A"
while retry_count < max_retries:
try:
result = service.spreadsheets().values().get(
spreadsheetId=spreadsheet_id,
range=range_name
).execute()
values = result.get('values', [])
print(f"Debug - Number of rows in column A: {len(values)}")
return len(values) + 1
except HttpError as e:
if e.resp.status in [500, 503]:
retry_count += 1
sleep_time = backoff_factor ** retry_count + random.uniform(0, 1)
print(f"HttpError {e.resp.status} encountered. Retrying in {sleep_time:.1f} seconds...")
time.sleep(sleep_time)
else:
raise
raise Exception("Failed to retrieve last empty row after several retries")
# Function to append data to a Google Sheet
def append_data_to_sheet(spreadsheet_id, sheet_name, values):
if SEND_TO_GOOGLE_SHEETS:
service = get_sheets_service()
last_empty_row = find_last_empty_row(service, spreadsheet_id, sheet_name)
range_name = f"{sheet_name}!A{last_empty_row}"
body = {
'values': values
}
result = service.spreadsheets().values().append(
spreadsheetId=spreadsheet_id, range=range_name,
valueInputOption='RAW', body=body).execute()
return result
# Function to send data to the server
def send_data(data):
"""Send data to the server."""
if SEND_TO_VERCEL:
try:
# Include API key in the headers
headers = {'x-api-key': VERCEL_API_KEY}
response = requests.post(URL, json=data, headers=headers)
response.raise_for_status()
print(data)
print(headers)
print(f"Data sent to server: {response.text}")
except requests.exceptions.RequestException as e:
print(f"Failed to send data to server: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
# Function to send data to ThingSpeak
def send_data_to_thingspeak():
"""Send data to ThingSpeak."""
if SEND_TO_THINGSPEAK and thingspeak_buffer:
data = thingspeak_buffer.pop(0) # Get the first item in the buffer
payload = {
'api_key': THINGSPEAK_API_KEY,
'field1': data['temperature_C'],
'field2': data['temperature_F'],
'field3': data['humidityPercent'],
'field4': data['time'],
'field5': data['date']
}
try:
response = requests.get(THINGSPEAK_BASE_URL, params=payload)
print('Data posted to ThingSpeak', response.text)
except requests.exceptions.RequestException as e:
print('Failed to send data to ThingSpeak:', e)
# Function to save spreadsheet info to a file
def save_spreadsheet_info(spreadsheet_id, workbook_name, sheet_name):
info = {
'spreadsheet_id': spreadsheet_id,
'workbook_name': workbook_name,
'sheet_name': sheet_name
}
with open('spreadsheet_info.txt', 'w') as f:
json.dump(info, f)
# Function to load spreadsheet info from a file
def load_spreadsheet_info():
if os.path.exists('spreadsheet_info.txt'):
with open('spreadsheet_info.txt', 'r') as f:
info = json.load(f)
return info['spreadsheet_id'], info['workbook_name'], info['sheet_name']
return None, None, None
def main():
# Load spreadsheet info from file
spreadsheet_id, workbook_name, sheet_name = load_spreadsheet_info()
if spreadsheet_id is None or workbook_name is None or sheet_name is None:
# Initialize new sheet if no info found
workbook_name = 'your-workbook-name' # Replace with your Google Sheet ID
spreadsheet_id = 'your-spreadsheet-id' # Replace with your Google Sheet ID
sheet_name = 'Sheet1' # Adjust the sheet name as needed
max_cells = 5000000
# Initialize loop counter
i = 1
# Get current date and time for the new sheet name if needed
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
new_sheet_name = f"Pi-Sensor {current_time}" # New sheet name with date and time
# Check sheet size and create new sheet if necessary
if SEND_TO_GOOGLE_SHEETS:
spreadsheet_id, total_cells = check_sheet_size(spreadsheet_id, new_sheet_name)
print(f"Total cells in the sheet: {total_cells}")
if total_cells >= max_cells:
print("The sheet has reached the maximum cell limit. Creating a new sheet.")
spreadsheet_id = create_new_sheet(new_sheet_name)
sheet_name = 'Sheet1' # Reset to default sheet name for new spreadsheet
else:
print("The sheet has not reached the maximum cell limit.")
# Time tracking for ThingSpeak
last_thingspeak_update = time_module.time()
while True:
# Get the current time at the start of the loop
start_time = time_module.time()
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
data = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
# Log data to buffer
data_buffer.append(data)
if i % 60 == 0:
print(f"Logged data: {data}")
# Append data to Google Sheet
append_data_to_sheet(spreadsheet_id, sheet_name, [[date, timeNow, humidityPercent, temperature_F, temperature_C]])
# Add data to ThingSpeak buffer
thingspeak_buffer.append({
'temperature_C': temperature_C,
'temperature_F': temperature_F,
'humidityPercent': humidityPercent,
'time': timeNow,
'date': date
})
# Check if 300 readings have been logged
if len(data_buffer) >= 300:
send_data(data_buffer)
# Clear the buffer after sending
data_buffer.clear()
i = 0
# Check if it's time to send data to ThingSpeak
if time_module.time() - last_thingspeak_update >= 15:
send_data_to_thingspeak()
last_thingspeak_update = time_module.time()
else:
# Handle cases where sensor fails to read
print("Failed to retrieve data from sensor")
# Wait until the LOOP_TIME has elapsed
while time_module.time() - start_time < LOOP_TIME:
time_module.sleep(0.01) # Sleep a short time to avoid busy-waiting
i += 1
if __name__ == '__main__':
main()Code Summary
This Python script reads environmental data from a DHT11 sensor, processes the data, and sends it to three different endpoints: Vercel, Google Sheets, and ThingSpeak. The script includes functionalities for authentication, data reading, data logging, and sending data to different services. Here is a summary of the main components and functionality:
Key Components:
Imports and Setup:
Imports necessary libraries for reading sensor data (
Adafruit_DHT), making HTTP requests (requests), handling time (time,datetime), and interacting with Google APIs (google.auth,google.oauth2,googleapiclient).Defines control flags to enable/disable sending data to Vercel, Google Sheets, and ThingSpeak.
API Key and Endpoint Configuration:
THINGSPEAK_API_KEYandTHINGSPEAK_BASE_URLfor ThingSpeak.VERCEL_API_KEYandURLfor Vercel.Google Sheets and Drive API scopes are defined.
Sensor Setup:
- Defines the DHT11 sensor and the GPIO pin to which it is connected.
Data Buffers:
- Initializes buffers for storing data before sending it to Vercel and ThingSpeak.
Google Sheets Authentication:
get_sheets_service(): Authenticates and returns the Google Sheets service object.get_drive_service(): Authenticates and returns the Google Drive service object.
Google Sheets Management:
set_sheet_public(spreadsheet_id): Sets the permissions of a Google Sheet to public.create_new_sheet(sheet_name): Creates a new Google Sheet with the specified name.check_sheet_size(spreadsheet_id, new_sheet_name): Checks the size of a Google Sheet and creates a new one if necessary.find_last_empty_row(service, spreadsheet_id, sheet_name): Finds the last empty row in a Google Sheet.append_data_to_sheet(spreadsheet_id, sheet_name, values): Appends data to a Google Sheet.save_spreadsheet_info(spreadsheet_id, workbook_name, sheet_name): Saves Google Sheet info to a file.load_spreadsheet_info(): Loads Google Sheet info from a file.
Sending Data:
send_data(data): Sends data to the Vercel endpoint.send_data_to_thingspeak(): Sends data to the ThingSpeak channel.
Main Function:
Loads spreadsheet info or initializes a new sheet.
Checks the size of the Google Sheet and creates a new one if it has reached its cell limit.
Enters an infinite loop to read data from the DHT11 sensor every second.
Prepares and logs data to buffers.
Appends data to Google Sheets.
Sends buffered data to Vercel every 300 readings.
Sends data to ThingSpeak every 15 seconds.
Includes error handling for sensor read failures and HTTP request failures.
Example Output:
- The script provides feedback through print statements, indicating the creation of new sheets, reading data, writing data, appending data, and handling errors.
Notes:
Replace
YOUR_API_KEYwith your actual ThingSpeak API key.Replace
YOURURLwith your actual Vercel endpoint URL.Replace
your-workbook-nameandyour-spreadsheet-idwith your actual Google Sheet name and ID.Ensure you have
credentials.jsonfor Google API OAuth 2.0 andtoken.jsonfor storing the user’s access and refresh tokens.
This script facilitates continuous monitoring and logging of environmental data from a DHT11 sensor, with automated data management and reporting using Vercel, Google Sheets, and ThingSpeak.
That’s 3 services down, with one more crack at MongoDB. The tentative plan is to push everything from the Python script then use some form of authentication to eventually be able to grab the data directly from MongoDB but use the Vercel site to “host” the csv/data. A rough sketch of the setup is below:
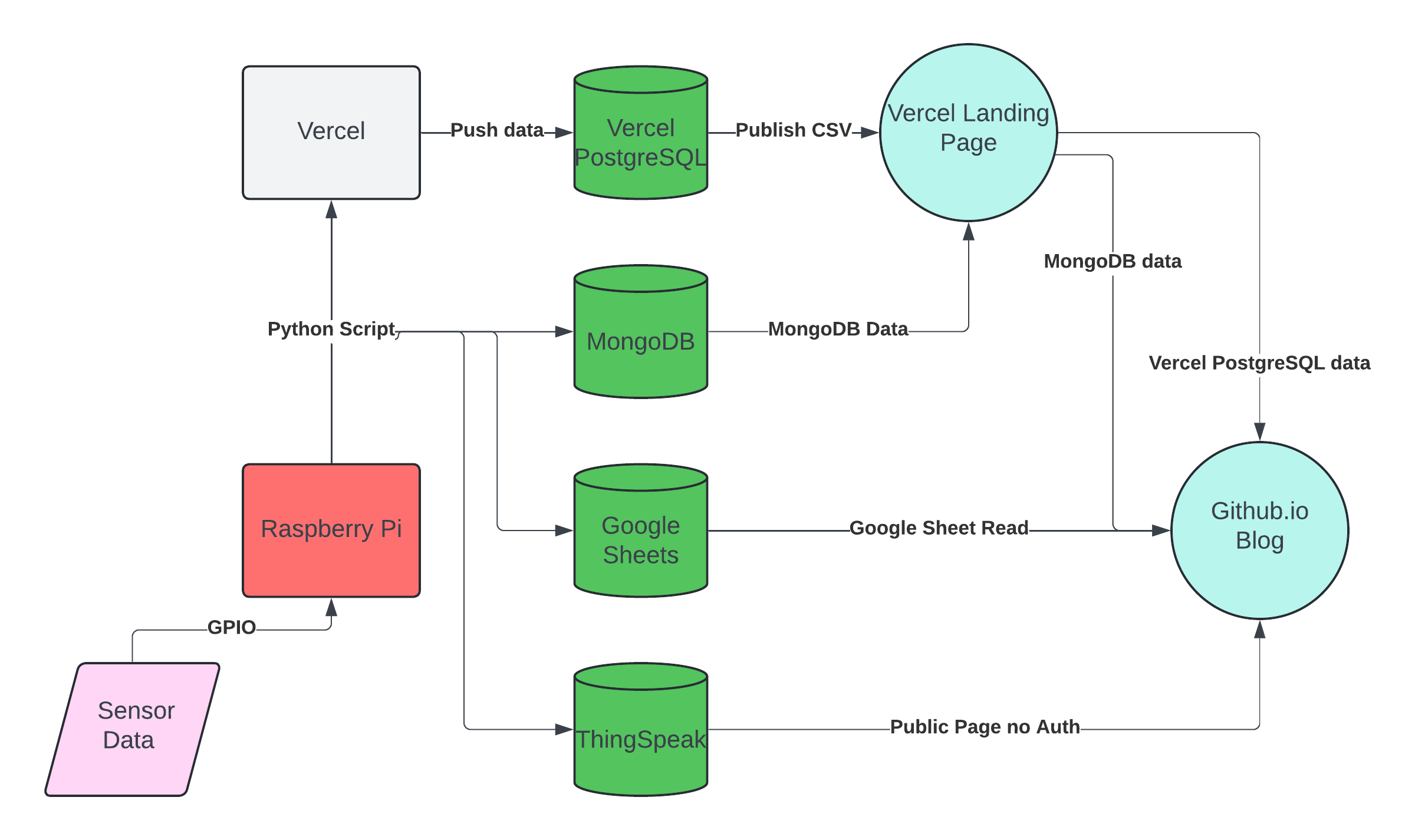
This was fairly straightforward and with one function and a couple of lines of Python I was all set up. Note that I changed the timings, notably Vercel. As the server spins up and stays active for 5 minutes after it receives data. The limit for Compute time is 60 hrs/month, so at the basic vCPU of 0.6 I will be at 0.6*(5minutes/60minutes)*24hour*30days=36 hours if I update it hourly. This is just safe enough for me to do and as a bonus its not like this is an AWS instance with my Credit Card linked.
Timings:
| Database | Update Interval | Capacity |
| Google Sheets | 1 second(with network delay more like 2) | 2 million entries(10 million cells) |
| ThingSpeak | 15 seconds(bulk update works around this) | 2 million entries(this is suspicious…) |
| MongoDB | 60 seconds | 512mb |
| Vercel PostgreSQL | 3600 seconds | 256mb |
Code
import os
import time as time_module
import requests
from datetime import datetime
import random
import json
import subprocess
import Adafruit_DHT
from pymongo import MongoClient
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# Control flags
SEND_TO_VERCEL = True
SEND_TO_GOOGLE_SHEETS = True
SEND_TO_THINGSPEAK = True
SEND_TO_MONGODB = True
# ThingSpeak API settings
THINGSPEAK_API_KEY = 'Your-API-Key'# Replace with your ThingSpeak API key
THINGSPEAK_BASE_URL = 'https://api.thingspeak.com/update'
THINGSPEAK_CHANNEL_ID = 000000 'Replace with your channel ID
THINGSPEAK_BULK_UPDATE_URL = 'https://api.thingspeak.com/channels/'+str(THINGSPEAK_CHANNEL_ID)+'/bulk_update.json'
print(THINGSPEAK_BULK_UPDATE_URL)
VERCEL_API_KEY = 'Your-Vercel-ID'
MONGODB_URI = 'mongodb+srv://<user>:<password>@<cluster-number>.<specialURL>.mongodb.net'
MONGODB_DB_NAME = 'Raspberry_Pi' #Your DB Name
MONGODB_COLLECTION_NAME = 'Readings'#Your Collection Name
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Vercel endpoint URL
URL = 'https://your-vercel-url.vercel.app/api/sensor'
# Buffer to store data
data_buffer_vercel = []
data_buffer_mongodb = []
thingspeak_buffer = [] # Buffer for ThingSpeak data
# Define loop time in seconds
LOOP_TIME = 1 # You can change this to the desired loop time in seconds
# Define the scopes required for the Google Sheets and Drive APIs
SCOPES = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive.file'
]
# Global variable to hold credentials
creds = None
# Function to get authenticated Sheets service
def get_sheets_service():
global creds
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.json', 'w') as token:
token.write(creds.to_json())
return build('sheets', 'v4', credentials=creds)
# Function to get authenticated Drive service
def get_drive_service():
global creds
if creds is None:
get_sheets_service() # This will initialize creds
return build('drive', 'v3', credentials=creds)
# Function to set a Google Sheet's permissions to public
def set_sheet_public(spreadsheet_id):
drive_service = get_drive_service()
permission = {
'type': 'anyone',
'role': 'reader'
}
try:
drive_service.permissions().create(fileId=spreadsheet_id, body=permission).execute()
print(f"Set spreadsheet with ID {spreadsheet_id} to public")
except HttpError as error:
print(f"An error occurred: {error}")
# Function to create a new Google Sheet with a given name
def create_new_sheet(sheet_name):
service = get_sheets_service()
spreadsheet = {
'properties': {
'title': sheet_name
}
}
spreadsheet = service.spreadsheets().create(body=spreadsheet, fields='spreadsheetId').execute()
spreadsheet_id = spreadsheet.get('spreadsheetId')
print(f"Created new spreadsheet with ID: {spreadsheet_id}, Name: {sheet_name}")
# Set the new sheet to be publicly viewable
set_sheet_public(spreadsheet_id)
# Save the new spreadsheet info
save_spreadsheet_info(spreadsheet_id, sheet_name, "Sheet1")
return spreadsheet_id
# Function to check the number of cells in the Google Sheet and create a new one if it doesn't exist
def check_sheet_size(spreadsheet_id, new_sheet_name):
service = get_sheets_service()
try:
sheet = service.spreadsheets().get(spreadsheetId=spreadsheet_id).execute()
sheets = sheet.get('sheets', [])
except HttpError as e:
print(f"HttpError encountered: Status code: {e.resp.status}, Reason: {e.error_details}")
if e.resp.status == 404:
print(f"Spreadsheet with ID '{spreadsheet_id}' not found. Creating a new sheet.")
return create_new_sheet(new_sheet_name), 0
else:
raise
total_cells = 0
for sheet in sheets:
properties = sheet.get('properties', {})
grid_properties = properties.get('gridProperties', {})
rows = grid_properties.get('rowCount', 0)
cols = grid_properties.get('columnCount', 0)
total_cells += rows * cols
return spreadsheet_id, total_cells
# Function to find the last empty row in the Google Sheet
def find_last_empty_row(service, spreadsheet_id, sheet_name,i):
max_retries = 5
retry_count = 0
backoff_factor = 2
range_name = f"{sheet_name}!A:A"
while retry_count < max_retries:
try:
result = service.spreadsheets().values().get(
spreadsheetId=spreadsheet_id,
range=range_name
).execute()
values = result.get('values', [])
if i%15==0:
print(f"Debug Google - Number of rows in column A: {len(values)}")
return len(values) + 1
except HttpError as e:
if e.resp.status in [500, 503]:
retry_count += 1
sleep_time = backoff_factor ** retry_count + random.uniform(0, 1)
print(f"HttpError {e.resp.status} encountered. Retrying in {sleep_time:.1f} seconds...")
time.sleep(sleep_time)
else:
raise
raise Exception("Failed to retrieve last empty row after several retries")
# Function to append data to a Google Sheet
def append_data_to_sheet(spreadsheet_id, sheet_name, values,i):
if SEND_TO_GOOGLE_SHEETS:
service = get_sheets_service()
last_empty_row = find_last_empty_row(service, spreadsheet_id, sheet_name,i)
range_name = f"{sheet_name}!A{last_empty_row}"
body = {
'values': values
}
result = service.spreadsheets().values().append(
spreadsheetId=spreadsheet_id, range=range_name,
valueInputOption='RAW', body=body).execute()
return result
# Function to send data to the server
def send_data_vercel(data):
"""Send data to the server."""
if SEND_TO_VERCEL:
try:
# Include API key in the headers
headers = {'x-api-key': VERCEL_API_KEY}
print(data)
print(headers)
response = requests.post(URL, json=data, headers=headers)
response.raise_for_status()
#print(data)
#print(headers)
print(f"Data sent to Vercel server: {response.text}")
except requests.exceptions.RequestException as e:
print(f"Failed to send data to server: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
# Function to send data to ThingSpeak
def thingspeak_update():
"""Send data to ThingSpeak."""
if SEND_TO_THINGSPEAK and thingspeak_buffer:
if len(thingspeak_buffer) > 1:
# Bulk update
payload = {
'write_api_key': THINGSPEAK_API_KEY,
'updates': []
}
#print(THINGSPEAK_API_KEY)
# Convert buffer data to the format required by ThingSpeak
for data in thingspeak_buffer:
update = {
'created_at': f"{data['date']} {data['time']} -0500",
'field1': data['temperature_C'],
'field2': data['temperature_F'],
'field3': data['humidityPercent'],
'field4': data['time'],
'field5': data['date']
}
payload['updates'].append(update)
try:
# Send the bulk update request to ThingSpeak
headers = {'Content-Type': 'application/json'}
#print(len(thingspeak_buffer))
#print(headers)
#print(json.dumps(payload))
# Convert the data payload to JSON format
json_data = json.dumps(payload)
response = requests.post(THINGSPEAK_BULK_UPDATE_URL,headers=headers,data=json_data)
if response.status_code == 202:
print('Data posted to ThingSpeak (bulk update):', response.text)
thingspeak_buffer.clear() # Clear the buffer after successful update
else:
print(f'Failed to send data to ThingSpeak (bulk update): {response.status_code}, {response.text}')
except requests.exceptions.RequestException as e:
print('Failed to send data to ThingSpeak (bulk update):', e)
else:
# Simple update
data = thingspeak_buffer[0]
payload = {
'api_key': THINGSPEAK_API_KEY,
'field1': data['temperature_C'],
'field2': data['temperature_F'],
'field3': data['humidityPercent'],
'field4': data['time'],
'field5': data['date'],
'created_at': f"{data['date']}T{data['time']}Z"
}
try:
# Send the simple update request to ThingSpeak
headers = {
'User-Agent': 'mw.doc.simple-update (Raspberry Pi)',
'Content-Type': 'application/x-www-form-urlencoded'
}
response = requests.post(THINGSPEAK_BASE_URL, headers=headers, params=payload)
if response.status_code == 200:
print('Data posted to ThingSpeak (simple update):', response.text)
thingspeak_buffer.clear() # Clear the buffer after successful update
else:
print(f'Failed to send data to ThingSpeak (simple update): {response.status_code}, {response.text}')
except requests.exceptions.RequestException as e:
print('Failed to send data to ThingSpeak (simple update):', e)
# Function to send data to MongoDB
def send_data_mongodb(data_mongo):
"""Send data to MongoDB."""
if SEND_TO_MONGODB:
try:
client = MongoClient(MONGODB_URI)
db = client[MONGODB_DB_NAME]
collection = db[MONGODB_COLLECTION_NAME]
result = collection.insert_many(data_mongo)
print(f"Data sent to MongoDB: {result.inserted_ids}")
except Exception as e:
print(f"Failed to send data to MongoDB: {e}")
# Function to save spreadsheet info to a file
def save_spreadsheet_info(spreadsheet_id, workbook_name, sheet_name):
info = {
'spreadsheet_id': spreadsheet_id,
'workbook_name': workbook_name,
'sheet_name': sheet_name
}
with open('spreadsheet_info.txt', 'w') as f:
json.dump(info, f)
# Function to load spreadsheet info from a file
def load_spreadsheet_info():
if os.path.exists('spreadsheet_info.txt'):
with open('spreadsheet_info.txt', 'r') as f:
info = json.load(f)
return info['spreadsheet_id'], info['workbook_name'], info['sheet_name']
return None, None, None
def main():
# Load spreadsheet info from file
spreadsheet_id, workbook_name, sheet_name = load_spreadsheet_info()
if spreadsheet_id is None or workbook_name is None or sheet_name is None:
# Initialize new sheet if no info found
workbook_name = 'your-workbook-name' # Replace with your Google Sheet ID
spreadsheet_id = 'your-spreadsheet-id' # Replace with your Google Sheet ID
sheet_name = 'Sheet1' # Adjust the sheet name as needed
max_cells = 5000000
# Initialize loop counter
i = 1
# Get current date and time for the new sheet name if needed
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
new_sheet_name = f"Pi-Sensor {current_time}" # New sheet name with date and time
# Check sheet size and create new sheet if necessary
if SEND_TO_GOOGLE_SHEETS:
spreadsheet_id, total_cells = check_sheet_size(spreadsheet_id, new_sheet_name)
print(f"Total cells in the sheet: {total_cells}")
if total_cells >= max_cells:
print("The sheet has reached the maximum cell limit. Creating a new sheet.")
spreadsheet_id = create_new_sheet(new_sheet_name)
sheet_name = 'Sheet1' # Reset to default sheet name for new spreadsheet
else:
print("The sheet has not reached the maximum cell limit.")
# Time tracking for ThingSpeak
last_thingspeak_update = time_module.time()
last_mongodb_update = time_module.time()
last_vercel_update = time_module.time()
while True:
# Get the current time at the start of the loop
start_time = time_module.time()
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
dataVercel = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
dataMongo = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
# Log data to buffer. had to separate data as sometimes ObjectID would somehow get passed to Vercel's buffer.
data_buffer_vercel.append(dataVercel)
data_buffer_mongodb.append(dataMongo)
if i % 60 == 0:
print(f"Logged data: {dataVercel}")
# Append data to Google Sheet
append_data_to_sheet(spreadsheet_id, sheet_name, [[date, timeNow, humidityPercent, temperature_F, temperature_C]],i)
# Add data to ThingSpeak buffer
thingspeak_buffer.append({
'temperature_C': temperature_C,
'temperature_F': temperature_F,
'humidityPercent': humidityPercent,
'time': timeNow,
'date': datetime.strptime(date, "%m-%d-%Y").strftime("%Y-%m-%d")
})
# Check if 300 readings have been logged
if time_module.time() - last_vercel_update >= 3600:
send_data_vercel(data_buffer_vercel)
# Clear the buffer after sending
data_buffer_vercel.clear()
last_vercel_update = time_module.time()
# Check if it's time to send data to Mongodb
if time_module.time() - last_mongodb_update >= 60:
send_data_mongodb(data_buffer_mongodb)
data_buffer_mongodb.clear()
last_mongodb_update = time_module.time()
# Check if it's time to send data to ThingSpeak
if time_module.time() - last_thingspeak_update >= 15:
thingspeak_update()
last_thingspeak_update = time_module.time()
else:
# Handle cases where sensor fails to read
print("Failed to retrieve data from sensor")
# Wait until the LOOP_TIME has elapsed
while time_module.time() - start_time < LOOP_TIME:
time_module.sleep(0.01) # Sleep a short time to avoid busy-waiting
i += 1
if __name__ == '__main__':
main()Code Summary
This Python script reads environmental data from a DHT11 sensor and sends it to multiple endpoints: Vercel, Google Sheets, ThingSpeak, and MongoDB. The script also includes functionality for managing Google Sheets, such as creating new sheets and appending data to them. Below is a detailed summary of the main components and their functionality:
Key Components:
Imports and Setup:
Imports necessary libraries for reading sensor data, making HTTP requests, handling time, and interacting with Google APIs and MongoDB.
Defines control flags to enable/disable sending data to Vercel, Google Sheets, ThingSpeak, and MongoDB.
API Key and Endpoint Configuration:
ThingSpeak API settings including API key, base URL, channel ID, and bulk update URL.
Vercel API key.
MongoDB URI, database name, and collection name.
Sensor Setup:
- Defines the DHT11 sensor and the GPIO pin to which it is connected.
Data Buffers:
- Initializes buffers for storing data before sending it to Vercel, MongoDB, and ThingSpeak.
Google Sheets Authentication:
get_sheets_service(): Authenticates and returns the Google Sheets service object.get_drive_service(): Authenticates and returns the Google Drive service object.
Google Sheets Management:
set_sheet_public(spreadsheet_id): Sets the permissions of a Google Sheet to public.create_new_sheet(sheet_name): Creates a new Google Sheet with the specified name.check_sheet_size(spreadsheet_id, new_sheet_name): Checks the size of a Google Sheet and creates a new one if necessary.find_last_empty_row(service, spreadsheet_id, sheet_name, i): Finds the last empty row in a Google Sheet.append_data_to_sheet(spreadsheet_id, sheet_name, values, i): Appends data to a Google Sheet.save_spreadsheet_info(spreadsheet_id, workbook_name, sheet_name): Saves Google Sheet info to a file.load_spreadsheet_info(): Loads Google Sheet info from a file.
Sending Data:
send_data_vercel(data): Sends data to the Vercel endpoint.thingspeak_update(): Sends data to the ThingSpeak channel, either as a bulk update or a simple update.send_data_mongodb(data_mongo): Sends data to MongoDB.
Main Function:
Loads spreadsheet info or initializes a new sheet.
Checks the size of the Google Sheet and creates a new one if it has reached its cell limit.
Enters an infinite loop to read data from the DHT11 sensor every second.
Prepares and logs data to buffers.
Appends data to Google Sheets.
Sends buffered data to Vercel every hour.
Sends data to MongoDB every 60 seconds.
Sends data to ThingSpeak every 15 seconds.
Includes error handling for sensor read failures and HTTP request failures.
Example Output:
- The script provides feedback through print statements, indicating the creation of new sheets, reading data, writing data, appending data, and handling errors.
Notes:
Replace
'Your-API-Key','Your-Vercel-ID', and'mongodb+srv://<user>:<password>@<cluster-number>.<specialURL>.mongodb.net'with your actual API keys and URIs.Replace
your-workbook-nameandyour-spreadsheet-idwith your actual Google Sheet name and ID.Ensure you have
credentials.jsonandtoken.jsonfiles for Google API OAuth 2.0 and token management.
This script facilitates continuous monitoring and logging of environmental data from a DHT11 sensor, with automated data management and reporting using Vercel, Google Sheets, ThingSpeak, and MongoDB.
Currently, sending to all 4 servers, I experience a max “drop” of the sensor data of 3 seconds and that is running a .py file with a desktop running in the background.
To set up the .py script to start up at boot I did the following:
And within that file:
[Unit]
Description=Sensor Data Collection Service
After=network.target
[Service]
ExecStart=/usr/local/bin/python3.12 /home/pi/Desktop/TempHumidityVercelGoogleMongoThinkSpeak.py
WorkingDirectory=/home/pi/Desktop
StandardOutput=append:/home/pi/sensor_data.log
StandardError=append:/home/pi/sensor_data.log
Restart=always
User=pi
[Install]
WantedBy=multi-user.targetThis sets it up to run at boot and also to log the output.
Enable and start the service:
Check the status:
I made a separate service file to make sure I can see the log by firing up my pi and leaving it be:
And within that file:
/home/pi/sensor_data.log {
daily
missingok
rotate 7
compress
delaycompress
notifempty
create 0640 pi pi
postrotate
systemctl restart sensor_data.service > /dev/null
endscript
}This will rotate the log file daily, keep 7 rotations, compress the old logs, and restart the service after every log rotation.
Next set up a script that checks for specific keywords including errors and sends a notification:
#!/bin/bash
LOG_FILE="/home/pi/sensor_data.log"
ERROR_KEYWORDS=("ERROR" "FAIL" "exception")
for keyword in "${ERROR_KEYWORDS[@]}"; do
if grep -q "$keyword" "$LOG_FILE"; then
echo "Error detected in sensor_data service logs:"
grep "$keyword" "$LOG_FILE"
break
fi
doneMake it executable:
Access Cron to schedule jobs:
Set the job to run * * * * *, or every minute of every hour of every day of every month.
Check that it worked:
From here I also wanted to display the output at boot as well. This is optional, but I wanna see a running log of what’s going on:
[Unit]
Description=Monitor Sensor Data Service Logs
After=sensor_data.service
Requires=sensor_data.service
[Service]
ExecStart=/bin/bash -c 'journalctl -u sensor_data.service -f'
StandardOutput=inherit
StandardError=inherit
Restart=always
User=pi
[Install]
WantedBy=multi-user.targetEnable on boot:
Disabling the desktop[Boot into Command Line Interface]:



Finally reboot and you’re done!
After setting up the python script to run at bootup and disabling the desktop I experience a drop of “1-2” seconds with a larger amount of 1 second drops than 2.
I must have made some sort of mistake in getting the logging to work, but the data is being sent and that’s good enough for now.
Running this command after the pi boots up works well enough:
And don’t forget that if you want to connect via SSH(if you didn’t already)”
If you want to get the desktop back simply type into the Pi console:
Now for the results:
To get the Google Script working I deployed a Google Aps Script:
Go to script.google.com and create a new project
Write a function to fetch data from my Google Sheets:
function doGet(e) {
try {
// Open the spreadsheet by ID and get the specified sheet
const sheet = SpreadsheetApp.openById('1n4iZYfgdhv08PeREqz26F4-eQYfnXdHaSQywnQ8UYWk').getSheetByName('Sheet1');
Logger.log('Sheet accessed successfully');
// Get the last row number
const lastRow = sheet.getLastRow();
Logger.log('Last row number: ' + lastRow);
// Get the values of the last row
const lastRowData = sheet.getRange(lastRow, 1, 1, sheet.getLastColumn()).getValues()[0];
Logger.log('Last row data: ' + JSON.stringify(lastRowData));
// Get the headers from the first row
const headers = sheet.getRange(1, 1, 1, sheet.getLastColumn()).getValues()[0];
Logger.log('Headers: ' + JSON.stringify(headers));
// Create an object to store the last row data
const result = {};
// Populate the result object with the headers as keys and last row data as values
headers.forEach((header, index) => {
result[header] = lastRowData[index];
});
Logger.log('Result object: ' + JSON.stringify(result));
// Convert the result object to JSON
const json = JSON.stringify(result);
// Set CORS headers
const output = ContentService.createTextOutput(json).setMimeType(ContentService.MimeType.JSON);
return output;
} catch (error) {
Logger.log('Error: ' + error.message);
return ContentService.createTextOutput(JSON.stringify({ error: error.message })).setMimeType(ContentService.MimeType.JSON);
}
}Deploy the script as a web app:
Click on the “Deploy” button.
Choose “Manage Deployments”.
Click “New Deployment”.
Select “Web app”.
Set “Execute the app as” to “Me” and “Who has access” to “Anyone”.
And then finally use the web app URL in my client-side code. Note that I tried fetching it manually, but got a:
Access to fetch at 'https://docs.google.com/spreadsheets/d/1n4iZYfgdhv08PeREqz26F4-eQYfnXdHaSQywnQ8UYWk/gviz/tq?tqx=out:json&sheet=Sheet1&range=A:E' from origin 'null' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.Latest sensor reading Google Sheets(button loads latest data):
Google Sheets Data Display
| Date | Time | Humidity % | Temp F | Temp C |
|---|
Latest Sensor Reading ThingSpeak(press button):
ThingSpeak Data Display
| Date | Time | Humidity % | Temp F | Temp C |
|---|
Configuring MongoDB to grab the sensor readings and the CSV required me to do quite a bit of configuring of Vercel(timeout increase) and making sure that the MongoDB was no longer using fixed IP addresses(I’m not implementing some cursed dynamic IP allocation). I also implement a 3 second wait just in case there’s a lot of requests/readers(unlikely).
Latest Sensor Reading MongoDB(Read-Only User):
MongoDB Data Display
Download MongoDB Table Data as CSV| Date | Time | Humidity % | Temp F | Temp C |
|---|
Latest Sensor Reading Vercel PostgreSQL(Read-Only User):
Vercel Data Display
Download Vercel Table Data as CSV| Date | Time | Humidity % | Temp F | Temp C |
|---|
Final Python Script on the off chance something changed:
*Note you can run with this pretty easily, change the flags to True for whatever “database” you’re using.*
Code
import os
import time as time_module
import requests
from datetime import datetime
import random
import json
import subprocess
import Adafruit_DHT
from pymongo import MongoClient
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# Control flags
SEND_TO_VERCEL = True
SEND_TO_GOOGLE_SHEETS = True
SEND_TO_THINGSPEAK = True
SEND_TO_MONGODB = True
# ThingSpeak API settings
THINGSPEAK_API_KEY = 'YOUR-THINGSPEAK-API-KEY' # Replace with your ThingSpeak API key
THINGSPEAK_BASE_URL = 'https://api.thingspeak.com/update'
THINGSPEAK_CHANNEL_ID = 00000000 #CHANGE ME
THINGSPEAK_BULK_UPDATE_URL = 'https://api.thingspeak.com/channels/'+str(THINGSPEAK_CHANNEL_ID)+'/bulk_update.json'
print(THINGSPEAK_BULK_UPDATE_URL)
VERCEL_API_KEY = 'YOUR-VERCEL-API-KEY'
MONGODB_URI = 'mongodb+srv://<USERNAME>:<PASSWORD>@cluster0.YOUR-URL.mongodb.net'
MONGODB_DB_NAME = 'Raspberry_Pi'
MONGODB_COLLECTION_NAME = 'Readings'
# Sensor setup
SENSOR = Adafruit_DHT.DHT11 # Using DHT11 sensor
PIN = 4 # Change this to the GPIO pin number that the sensor is connected to
# Vercel endpoint URL
URL = 'https://YOUR-VERCEL-URL.vercel.app/api/sensor'
# Buffer to store data
data_buffer_vercel = []
data_buffer_mongodb = []
thingspeak_buffer = [] # Buffer for ThingSpeak data
# Define loop time in seconds
LOOP_TIME = 1 # You can change this to the desired loop time in seconds
# Define the scopes required for the Google Sheets and Drive APIs
SCOPES = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive.file'
]
# Global variable to hold credentials
creds = None
# Function to get authenticated Sheets service
def get_sheets_service():
global creds
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.json', 'w') as token:
token.write(creds.to_json())
return build('sheets', 'v4', credentials=creds)
# Function to get authenticated Drive service
def get_drive_service():
global creds
if creds is None:
get_sheets_service() # This will initialize creds
return build('drive', 'v3', credentials=creds)
# Function to set a Google Sheet's permissions to public
def set_sheet_public(spreadsheet_id):
drive_service = get_drive_service()
permission = {
'type': 'anyone',
'role': 'reader'
}
try:
drive_service.permissions().create(fileId=spreadsheet_id, body=permission).execute()
print(f"Set spreadsheet with ID {spreadsheet_id} to public")
except HttpError as error:
print(f"An error occurred: {error}")
# Function to create a new Google Sheet with a given name
def create_new_sheet(sheet_name):
service = get_sheets_service()
spreadsheet = {
'properties': {
'title': sheet_name
}
}
spreadsheet = service.spreadsheets().create(body=spreadsheet, fields='spreadsheetId').execute()
spreadsheet_id = spreadsheet.get('spreadsheetId')
print(f"Created new spreadsheet with ID: {spreadsheet_id}, Name: {sheet_name}")
# Set the new sheet to be publicly viewable
set_sheet_public(spreadsheet_id)
# Save the new spreadsheet info
save_spreadsheet_info(spreadsheet_id, sheet_name, "Sheet1")
return spreadsheet_id
# Function to check the number of cells in the Google Sheet and create a new one if it doesn't exist
def check_sheet_size(spreadsheet_id, new_sheet_name):
service = get_sheets_service()
try:
sheet = service.spreadsheets().get(spreadsheetId=spreadsheet_id).execute()
sheets = sheet.get('sheets', [])
except HttpError as e:
print(f"HttpError encountered: Status code: {e.resp.status}, Reason: {e.error_details}")
if e.resp.status == 404:
print(f"Spreadsheet with ID '{spreadsheet_id}' not found. Creating a new sheet.")
return create_new_sheet(new_sheet_name), 0
else:
raise
total_cells = 0
for sheet in sheets:
properties = sheet.get('properties', {})
grid_properties = properties.get('gridProperties', {})
rows = grid_properties.get('rowCount', 0)
cols = grid_properties.get('columnCount', 0)
total_cells += rows * cols
return spreadsheet_id, total_cells
# Function to find the last empty row in the Google Sheet
def find_last_empty_row(service, spreadsheet_id, sheet_name,i):
max_retries = 5
retry_count = 0
backoff_factor = 2
range_name = f"{sheet_name}!A:A"
while retry_count < max_retries:
try:
result = service.spreadsheets().values().get(
spreadsheetId=spreadsheet_id,
range=range_name
).execute()
values = result.get('values', [])
if i%15==0:
print(f"Debug Google - Number of rows in column A: {len(values)}")
return len(values) + 1
except HttpError as e:
if e.resp.status in [500, 503]:
retry_count += 1
sleep_time = backoff_factor ** retry_count + random.uniform(0, 1)
print(f"HttpError {e.resp.status} encountered. Retrying in {sleep_time:.1f} seconds...")
time.sleep(sleep_time)
else:
raise
raise Exception("Failed to retrieve last empty row after several retries")
# Function to append data to a Google Sheet
def append_data_to_sheet(spreadsheet_id, sheet_name, values,i):
if SEND_TO_GOOGLE_SHEETS:
service = get_sheets_service()
last_empty_row = find_last_empty_row(service, spreadsheet_id, sheet_name,i)
range_name = f"{sheet_name}!A{last_empty_row}"
body = {
'values': values
}
result = service.spreadsheets().values().append(
spreadsheetId=spreadsheet_id, range=range_name,
valueInputOption='RAW', body=body).execute()
return result
# Function to send data to the server
def send_data_vercel(data):
"""Send data to the server."""
if SEND_TO_VERCEL:
try:
# Include API key in the headers
headers = {'x-api-key': VERCEL_API_KEY}
print(data)
print(headers)
response = requests.post(URL, json=data, headers=headers)
response.raise_for_status()
#print(data)
#print(headers)
print(f"Data sent to Vercel server: {response.text}")
except requests.exceptions.RequestException as e:
print(f"Failed to send data to server: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
# Function to send data to ThingSpeak
def thingspeak_update():
"""Send data to ThingSpeak."""
if SEND_TO_THINGSPEAK and thingspeak_buffer:
if len(thingspeak_buffer) > 1:
# Bulk update
payload = {
'write_api_key': THINGSPEAK_API_KEY,
'updates': []
}
#print(THINGSPEAK_API_KEY)
# Convert buffer data to the format required by ThingSpeak
for data in thingspeak_buffer:
update = {
'created_at': f"{data['date']} {data['time']} -0500",
'field1': data['temperature_C'],
'field2': data['temperature_F'],
'field3': data['humidityPercent'],
'field4': data['time'],
'field5': data['date']
}
payload['updates'].append(update)
try:
# Send the bulk update request to ThingSpeak
headers = {'Content-Type': 'application/json'}
#print(len(thingspeak_buffer))
#print(headers)
#print(json.dumps(payload))
# Convert the data payload to JSON format
json_data = json.dumps(payload)
response = requests.post(THINGSPEAK_BULK_UPDATE_URL,headers=headers,data=json_data)
if response.status_code == 202:
print('Data posted to ThingSpeak (bulk update):', response.text)
thingspeak_buffer.clear() # Clear the buffer after successful update
else:
print(f'Failed to send data to ThingSpeak (bulk update): {response.status_code}, {response.text}')
except requests.exceptions.RequestException as e:
print('Failed to send data to ThingSpeak (bulk update):', e)
else:
# Simple update
data = thingspeak_buffer[0]
payload = {
'api_key': THINGSPEAK_API_KEY,
'field1': data['temperature_C'],
'field2': data['temperature_F'],
'field3': data['humidityPercent'],
'field4': data['time'],
'field5': data['date'],
'created_at': f"{data['date']}T{data['time']}Z"
}
try:
# Send the simple update request to ThingSpeak
headers = {
'User-Agent': 'mw.doc.simple-update (Raspberry Pi)',
'Content-Type': 'application/x-www-form-urlencoded'
}
response = requests.post(THINGSPEAK_BASE_URL, headers=headers, params=payload)
if response.status_code == 200:
print('Data posted to ThingSpeak (simple update):', response.text)
thingspeak_buffer.clear() # Clear the buffer after successful update
else:
print(f'Failed to send data to ThingSpeak (simple update): {response.status_code}, {response.text}')
except requests.exceptions.RequestException as e:
print('Failed to send data to ThingSpeak (simple update):', e)
# Function to send data to MongoDB
def send_data_mongodb(data_mongo):
"""Send data to MongoDB."""
if SEND_TO_MONGODB:
try:
client = MongoClient(MONGODB_URI)
db = client[MONGODB_DB_NAME]
collection = db[MONGODB_COLLECTION_NAME]
result = collection.insert_many(data_mongo)
print(f"Data sent to MongoDB: {result.inserted_ids}")
except Exception as e:
print(f"Failed to send data to MongoDB: {e}")
# Function to initialize the current count of the index from MongoDB
#I was debating on introducing an index to make sure I knew what the current count of values was..
#But that seemed pretty wasteful.
# def initialize_index():
# global index
# try:
# client = MongoClient(MONGODB_URI)
# db = client[MONGODB_DB_NAME]
# collection = db[MONGODB_COLLECTION_NAME]
# last_entry = collection.find().sort([('_id', -1)]).limit(1)
# if last_entry.count() > 0:
# index = last_entry[0].get('index', 0) + 1
# else:
# index = 1
# print(f"Index initialized to {index}")
# except Exception as e:
# print(f"Failed to initialize index: {e}")
# Function to save spreadsheet info to a file
def save_spreadsheet_info(spreadsheet_id, workbook_name, sheet_name):
info = {
'spreadsheet_id': spreadsheet_id,
'workbook_name': workbook_name,
'sheet_name': sheet_name
}
with open('spreadsheet_info.txt', 'w') as f:
json.dump(info, f)
# Function to load spreadsheet info from a file
def load_spreadsheet_info():
if os.path.exists('spreadsheet_info.txt'):
with open('spreadsheet_info.txt', 'r') as f:
info = json.load(f)
return info['spreadsheet_id'], info['workbook_name'], info['sheet_name']
return None, None, None
def main():
# Load spreadsheet info from file
spreadsheet_id, workbook_name, sheet_name = load_spreadsheet_info()
if spreadsheet_id is None or workbook_name is None or sheet_name is None:
# Initialize new sheet if no info found
workbook_name = 'your-workbook-name' # Replace with your Google Sheet ID
spreadsheet_id = 'your-spreadsheet-id' # Replace with your Google Sheet ID
sheet_name = 'Sheet1' # Adjust the sheet name as needed
max_cells = 5000000
# Initialize loop counter
i = 1
# Get current date and time for the new sheet name if needed
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
new_sheet_name = f"Pi-Sensor {current_time}" # New sheet name with date and time
# Check sheet size and create new sheet if necessary
if SEND_TO_GOOGLE_SHEETS:
spreadsheet_id, total_cells = check_sheet_size(spreadsheet_id, new_sheet_name)
print(f"Total cells in the sheet: {total_cells}")
if total_cells >= max_cells:
print("The sheet has reached the maximum cell limit. Creating a new sheet.")
spreadsheet_id = create_new_sheet(new_sheet_name)
sheet_name = 'Sheet1' # Reset to default sheet name for new spreadsheet
else:
print("The sheet has not reached the maximum cell limit.")
# Time tracking for ThingSpeak
last_thingspeak_update = time_module.time()
last_mongodb_update = time_module.time()
last_vercel_update = time_module.time()
while True:
# Get the current time at the start of the loop
start_time = time_module.time()
# Read humidity and temperature from DHT sensor
humidityPercent, temperature_C = Adafruit_DHT.read_retry(SENSOR, PIN)
if humidityPercent is not None and temperature_C is not None:
# Prepare the data payload
temperature_F = temperature_C * 9.0 / 5.0 + 32
now = datetime.now()
date = now.strftime("%m-%d-%Y")
timeNow = now.strftime("%H:%M:%S")
dataVercel = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C
}
dataMongo = {
'date': date,
'time': timeNow,
'humidityPercent': humidityPercent,
'temperatureFahrenheit': temperature_F,
'temperatureCelsius': temperature_C,
}
# Log data to buffer. had to separate data as sometimes ObjectID would somehow get passed to Vercel's buffer.
data_buffer_vercel.append(dataVercel)
data_buffer_mongodb.append(dataMongo)
if i % 60 == 0:
print(f"Logged data: {dataVercel}")
# Append data to Google Sheet
append_data_to_sheet(spreadsheet_id, sheet_name, [[date, timeNow, humidityPercent, temperature_F, temperature_C]],i)
# Add data to ThingSpeak buffer
thingspeak_buffer.append({
'temperature_C': temperature_C,
'temperature_F': temperature_F,
'humidityPercent': humidityPercent,
'time': timeNow,
'date': datetime.strptime(date, "%m-%d-%Y").strftime("%Y-%m-%d")
})
# Check if 300 readings have been logged
if time_module.time() - last_vercel_update >= 3600:
send_data_vercel(data_buffer_vercel)
# Clear the buffer after sending
data_buffer_vercel.clear()
last_vercel_update = time_module.time()
# Check if it's time to send data to Mongodb
if time_module.time() - last_mongodb_update >= 60:
send_data_mongodb(data_buffer_mongodb)
data_buffer_mongodb.clear()
last_mongodb_update = time_module.time()
# Check if it's time to send data to ThingSpeak
if time_module.time() - last_thingspeak_update >= 15:
thingspeak_update()
last_thingspeak_update = time_module.time()
else:
# Handle cases where sensor fails to read
print("Failed to retrieve data from sensor")
# Wait until the LOOP_TIME has elapsed
while time_module.time() - start_time < LOOP_TIME:
time_module.sleep(0.01) # Sleep a short time to avoid busy-waiting
i += 1
if __name__ == '__main__':
main()And there you have it. 4 different databases and the ability to write/read to them in near real time via a simple web portal. I could have used any of these individually but I wanted to explore the strengths/weaknesses of different configurations. I like the idea of just using a pretty long Google Sheet for most projects and completely ignoring actual databases for simple home automation. Using MongoDB was pretty straightforward via VSCode and it is a strong second choice. Tying for second would be ThingSpeak with its cool online interface, but I’m wary of Mathworks in general with their pay to play scheme. Last place is definitely Vercel’s own implementation of PostgreSQL mostly because of the compute/size limitations.
I would have implemented multiple sensors, likely in the form of PM2.5/10, CO2, a better DHT22 sensor, and a VOC sensor. Here’s my Amazon wish list for future projects:
PM2.5/10[PMS5003]: https://www.adafruit.com/product/3686
CO2[MH-Z19]: https://www.amazon.com/EC-Buying-Monitoring-Concentration-Detection/dp/B0CRKH5XVX/
Temperature/Humidity[DHT22]: https://www.amazon.com/SHILLEHTEK-Digital-Temperature-Humidity-Sensor/dp/B0CN5PN225/
Temp/Humidity/Pressure/VOC[BME680]: https://www.amazon.com/CJMCU-680-Temperature-Humidity-Ultra-Small-Development/dp/B07K1CGQTJ/
Air Quality/VOC[MQ135]: https://www.amazon.com/Ximimark-Quality-Hazardous-Detection-Arduino/dp/B07L73VTTY/
While a description of extract, transform, and load(ETL) probably belongs up top I feel like it fits the narrative better to define it here and describe how this project is one giant homegrown ETL pipeline…
What is an ETL Pipeline?
Definition
ETL stands for Extract, Transform, Load. It’s a process used in data management to:
Extract data from various sources.
Transform the data into a suitable format or structure for analysis and reporting.
Load the transformed data into a target database, data warehouse, or data lake.
How it Works
Extract:
Data is collected from different sources like databases, APIs, files, or sensors.
This step involves connecting to the source, querying or retrieving the data, and pulling it into the pipeline.
Transform:
The extracted data is cleaned, validated, and transformed to fit the schema of the target system.
Transformations might include filtering, aggregating, joining, sorting, or converting data types.
This step ensures data quality and prepares it for efficient loading and querying in the target system.
Load:
The transformed data is loaded into the target database, data warehouse, or data lake.
This involves writing the data into the storage system, ensuring it’s available for querying and analysis.
The loading process can be a full load (overwriting existing data) or an incremental load (updating or adding new data).
Applications
ETL pipelines are used in various scenarios, including:
Data Warehousing: Collecting and consolidating data from multiple sources into a central repository for reporting and analysis.
Business Intelligence (BI): Providing clean and structured data for BI tools to generate insights and reports.
Data Integration: Integrating data from different systems to provide a unified view.
Data Migration: Moving data from one system to another, often during system upgrades or cloud migrations.
Data Analytics: Preparing data for analysis and machine learning models.
Example of a Homegrown ETL Pipeline in the Project
The project described above is a great example of a homegrown ETL pipeline, using a Raspberry Pi and various data storage solutions.
Extract
Data Sources: Environmental data is extracted from various sensors (e.g., DHT11 for temperature and humidity).
Data Collection: The sensors are connected to the Raspberry Pi, which reads data at regular intervals.
Transform
Data Processing: The raw data from the sensors is processed to convert it into a readable format (e.g., converting temperature from Celsius to Fahrenheit).
Data Formatting: The data is formatted into JSON objects for a consistent structure across different storage solutions.
Load
Data Storage: The transformed data is loaded into multiple storage solutions:
Google Sheets: For easy access and sharing.
ThingSpeak: For real-time visualization and monitoring.
MongoDB: For flexible, document-based storage.
Vercel PostgreSQL: For relational database storage.
How the Project Implements ETL
Extract:
- The Raspberry Pi reads data from the DHT11 sensor every second using the
Adafruit_DHTlibrary.
- The Raspberry Pi reads data from the DHT11 sensor every second using the
Transform:
The raw data (humidity and temperature) is processed to convert temperature to Fahrenheit and format the date and time.
The data is structured into JSON objects for consistency.
Load:
The data is sent to multiple endpoints:
Google Sheets: Using the Google Sheets API to append new rows.
ThingSpeak: Using the ThingSpeak API for both simple and bulk updates.
MongoDB: Using the MongoDB Python client to insert data into the collection.
Vercel PostgreSQL: Sending data to a Vercel serverless function which writes to a PostgreSQL database.
Benefits of this ETL Pipeline
Real-time Data Processing: The pipeline processes and loads data in near real-time, providing up-to-date information.
Multi-Storage Integration: The data is stored in various platforms, each with its strengths, ensuring data availability and flexibility.
Scalability: The modular approach allows easy addition of new sensors or data sources.
Automation: The use of scheduled tasks and services ensures continuous data collection and processing without manual intervention.
Conclusion
This project shows off a homegrown ETL pipeline that efficiently collects, processes, and stores environmental data from sensors. By using various storage solutions, it demonstrates how a flexible and scalable ETL process can be implemented for real-time data monitoring and analysis in a home automation context.